
Written by: Boris Asadanin, Streaming Media Consultant at Eyevinn Technology
Background
When recording a video professionally, the camera usually outputs an uncompressed video file. This file is the original with optimal quality. But with high quality comes large storage and high bandwidth. The higher quality video file, the more storage and bandwidth is required to store and distribute the file over a network. Both comes with cost and should be kept as low as possible while still retaining the quality.
Lowering the storage and bandwidth requirements means accepting trade-offs on quality. But there are good techniques today to compress and alter the original uncompressed video content to achieve an optimal quality/bandwidth ratio. This tutorial describes the concepts of encoding techniques used in today’s video streaming.
This publication is part of a series of articles describing the principles of the technology behind video streaming. It could be read without any prior knowledge on the subject.
What is Video
As kids we used to draw pictures on separate pages in a note pad and then fastly thumb our way between the pages. This would create a visible motion effect. Swiftly switching between similar still pictures creates this motion effect for the human eye. 20 pictures per second or more creates a smooth motion effect. Traditional TV and videos are recorded at around 24–30 frames per second depending on standards. But the frame rate is constantly increasing with better cameras, TVs, and networks.
So, a movie is really lots of consecutive pictures.

Video Encoding
Video encoding and compression is complex. Really complex. But let us go through the main principles.
What is video Encoding?
Video Encoding is a few techniques applied to a video file to optimize quality and minimize size to fit the target viewing device and distribution method. It differs quite much if the video is intended for viewing on smartphone devices or on big screen TV sets. First, the available screen size defines how the human eye perceives picture quality. If the video is intended for smaller screens we can accept bigger trade-off in quality to minimize video size. The human eye won’t notice the quality drop on a small screen. But if the video is intended to be viewed on a big screen TV, there is little quality trade-offs accepted before the human eye reacts to a bad picture experience. As a result, the video file size remains bigger.
The distribution method for the video must also be considered. Will it be streamed to 3G connected devices or to high speed fiber optic links? The latter obviously gives more leeway in setting the right video quality/size ratio.
Video Resolution
As mentioned, a video consists of lots of still pictures. So, what is a picture then?
Looking at digital video, each picture is built up in pixels where each pixel has a defined colour value and light value (colour values defined by chroma subsampling is beyond the scope of this tutorial). The more pixels per area unit, the finer quality video you are watching. I usually imagine picture quality as a chess board and will use chess boards throughout this tutorial.

There are two aspects to picture resolution when encoding video content to various quality levels.
Firstly, will each pixel be defined separately and independently, or will pixels be grouped into blocks of multiple pixels each? The former would yield a high quality video while the latter would create a lower quality video depending on how many pixels are grouped into each block.
Secondly, how many pixels in total is the goal? This is usually referred to as picture resolution and is quite known in computer graphics. But during the last ten years when the TV screen sizes have grown, the resolution has become an important aspect. Particularly in the TV industry there are a few standardized resolutions as shown in fig 3.
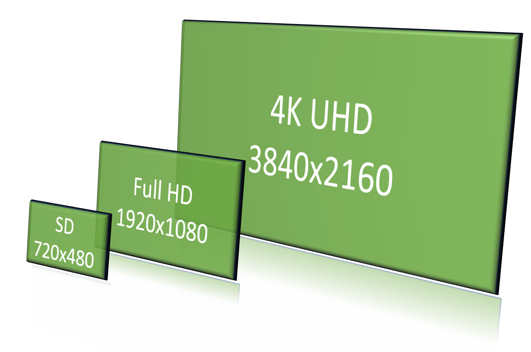
Of course, there are multiple other resolutions and aspect ratios called various things as Ultra HD, 2K, DV etc. As this tutorial aims to explain the concept we will stick to using the three mentioned.
So what is the best resolution? That obviously depends on the screen itself. Larger screens are made for larger resolutions and vice versa. Let us use the chess board example from above. The left board of fig 2 has clearly a higher resolution AND quality than the right board. Compared with fig 4 below the two boards have the same resolution difference as in fig 2. But quality wise the two boards in fig 4 are the same since the right board is much smaller.

Video Compression
Interlacing
Initially the bandwidth was too low for sending quality video. Interlacing was the solution to the bandwidth problem and became one of the first compression techniques, still in wide use today in linear broadcast SD and HD TV. The UHDTV standards have abandoned interlacing and use progressive picture only.
The idea behind interlacing is simply to split pictures in two by every second horizontal line. Each of the two pictures will be half the size, and simply putting them together again would yield a complete picture. Figure 5 below shows this using the chess board analogy again.
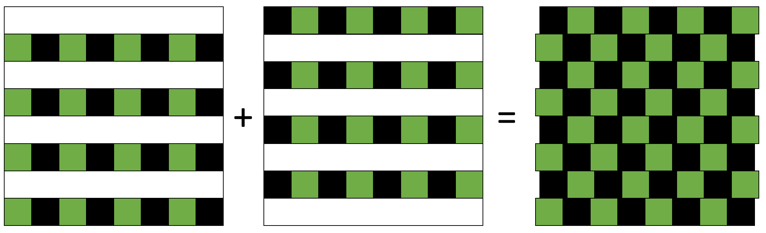
Interlacing videos cuts the bitrate by half. Except the quite static bandwidth saving the main drawback with interlacing is that the two half pictures come one after the other. Therefore, in a high motion video the interlaced complete picture will look slightly displaced horizontally which is also depicted in figure 5.
Interlacing is marked with an “i” together with the resolution in TV and camera specifications. The opposite to interlacing, progressive picture, is marked with a “p”.
Temporal Motion Compression
Later compressions techniques resulted in more effective and dynamic compression rates overcoming the drawbacks of interlacing. Looking at a quite slow tv show like the financial news there are few moving objects on the screen. Could we then reuse some of the pictures in the 24 picture set that we mentioned initially?

Imagine watching a live chess game. There are a few smaller movements but 98% of the picture is the same, sometimes even for more than a few seconds. Instead of using an original JPEG picture in our 24 picture set per second, can we exchange some of them to information about only the few changes from last real picture? This is the key question which is has been answered and defined by the MPEG standard.
The first picture must always be a reference picture — also known as an I-frame or a Reference Frame. The I-frames were referred to as “complete pictures” in the ABR tutorials. We will use the term I-frame throughout this tutorial. Think of it as a high-quality JPEG picture .This is the original picture that is used to define the subsequent pictures. The changes add up and after some time there will be too big/many changes from the first I-frame, especially after a scene change. It then becomes “cheaper” traffic wise and better quality wise to use another I-frame instead of continuing describing the changes. The video looks like this:

Each set of 12 pictures starts with an I-frame. The remaining 11 pictures, called P-frames, only define the mathematical delta from the preceding frame, I-frame or P-frame. After that comes another I-frame.

To get a better quality/bandwidth ratio, and to complicate things, more recent encoding technique have added a third and “cheaper” type of frame which is bi-directional. Instead of defining the delta from only the preceding frame, this bi-directional frame also defines the delta to subsequent frames. Using B-frames further compresses the video file while maintaining the quality.
Before completing the GOP explanation, let us define our new terminology:
- GOP: Group of pictures. The set of frames starting with an I-frame and to the next I-frame. In our scenario we are using a 12 framed GOP. GOPs may also be defined in seconds.
- I-frame: A good quality reference picture. Imagine this as an ordinary, high-quality JPEG still picture from the video.
- P-frame: A frame that consists a mathematical description of the delta since the preceding frame, I- or P-frame.
- B-frame: A bi-directional frame explaining delta between both frames before and coming frames. Only I- and P-frames.
Note: No frames explain the delta from a B-frame.
We are now ready to fully grasp the GOPs:
Again, each GOP starts with a high quality reference I-frame. The remaining frames within the GOP are either P-frames or B-frames. The P-frames explain the delta since the preceding I-frame OR P-frame. The B-frame contain the delta since the last I-frame or P-frame AND the delta to the subsequent I-frame or P-frame. Figure 9 hopefully explains this more clearly.
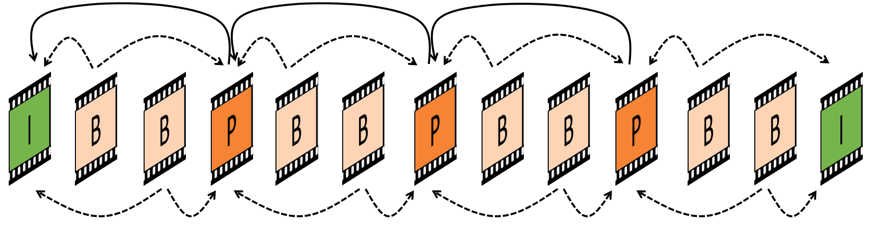
In summary, understanding the concept of P- and B-frames mathematically explaining the delta since preceding frames, together with the relational explanation in fig 9, defines the main principal behind video compression methodologies.
Video Compression and ABR Streaming
It is important to note that a video must start from an I-frame. As the P- and B-frames are completely useless without a grounding I-frame, starting a video mid-GOP is no use. The video player will not be able to decode any visual pictures until the next GOP is received. Put this in relation to the ABR streaming principles described in Internet Video Streaming — ABR tutorials; a video segment must begin with an I-frame. Segmenting the video must therefore always be aligned with GOPs to ensure smooth playback on segment switching.
The final section of ABR part 3 describes lowering latency and questions the minimum 2s segment lengths. Imagine lowering the segment lengths to 200ms, like in the ABR part 3 article. As each segment must be started with an I-frame, our GOP lengths would have to be maximum 200ms. This setup would maybe work fine but it would severely limit the compression level.
Final Words
Again, video compression techniques are really complex. There are many more techniques for defining colour and light to pictures and videos, but the main principles behind general video compression builds on GOPs and resolution standards as described in this tutorial. The Video Formats Overview tutorial focuses on the various technology standards and the difference between video encoding and formats.
Eyevinn Technology is the leading independent consultant firm specializing in video technology and media distribution, and proud organizer of the yearly nordic conference Streaming Tech Sweden.

